Réconcilier avec Datasette
Avertissement
- Cette partie de la documentation ne traite pas du service de réconciliation de Biblissima+. Si c’est ce sujet qui vous intéresse, voir la page Réconcilier ses données.
- L’outil datasette-reconcile permet de créer un service de réconciliation en local sur n’importe quel jeu de données téléchargé sur votre ordinateur. Ce tutoriel vous explique comment paramétrer ce service, et présente un cas d’utilisation à partir de noms d’auteurs à aligner avec les autorités BnF.
1.1 - Installation des outils¶
Datasette est un framework open-source Python qui permet de manipuler et publier ses données avec une interface web. Cet outil donne accès à de nombreux plugins qui ajoutent de nouvelles fonctionnalités.
Nous présentons ici le plugin datasette-reconcile qui permet la création d’un service de réconciliation des données qui suit les recommandations du W3C.
Avant de mettre en place l’outil de réconciliation, il faut d’abord installer datasette dans son environnement de travail (utilisable à partir de la version 3.9 de Python). Vous pouvez le faire en utilisant le module pip de Python :
pip install datasette
Pour ajouter des plugins, vous devez ensuite utiliser la commande intégrée datasette install suivie du nom du plugin, ici datasette-reconcile.
datasette install datasette-reconcile
Une fois ces deux commandes exécutées, il ne vous reste plus qu’à ajouter votre jeu de données et personnaliser les options de travail avec l’outil.
1.2 - Préparation du jeu de données¶
Le framework a besoin d’une base de données au format SQLite pour fonctionner. Pour créer une base dans ce format, il est tout à fait faisable de transformer un tableau CSV en fichier SQLite avec des outils comme DB Browser. Une fois que vous avez créé votre nouvelle base de données (appelons-la base_reconcile.db), vous pouvez importer votre fichier CSV qui va peupler cette base de données.
{kind=link}
Vous pouvez dès à présent lancer datasette sur cette base de données. L’interface s’ouvrira sur votre navigateur à l’adresse http://localhost:8001.
datasette base_reconcile.db
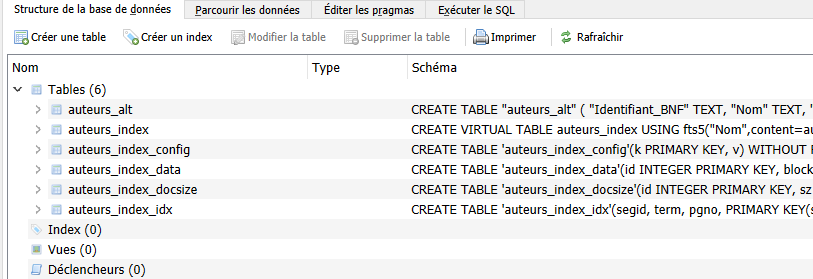
1.3 - Configuration du plugin de réconciliation¶
Le service de réconciliation n’est pas encore configuré. Pour ce faire, vous devez passer par les fichiers de métadonnées prévus par datasette au format JSON. Dans ce fichier JSON que vous allez devoir créer (ici nous l’appelerons config_reconcile.json), vous devez spécifier l’arborescence de l’outil, en indiquant tous les niveaux d’imbrication jusqu’à la table qui sera prise en compte par le plugin de réconciliation. C’est au niveau de cette table que doit être configuré le plugin.
1 2 3 4 5 6 7 8 | |
Vous avez ci-dessus la configuration minimale pour lancer le service. Le name_field est le seul champ obligatoire dans les métadonnées, il correspond au nom de la colonne qui sera interrogée lors de l’utilisation du service. Pour en savoir plus sur les différents outils de personnalisation du service, voir cette page. Les autres colonnes de la base de données, en dehors du name_field, peuvent être accessibles grâce au service data extension directement intégré.
Il ne vous reste plus qu’à relancer l’application en indiquant le chemin vers votre fichier, si aucun chemin n’est indiqué, datasette cherche le fichier dans le répertoire courant.
Vous devriez maintenant pouvoir accéder à votre service de réconciliation personnalisé à partir de la page http://localhost:8001/nom_de_la_base/nom_de_la_table/-/reconcile.
1.4 - Activer la recherche plein-texte (FTS)¶
L’utilisation de l’outil peut s’avérer assez limitée à cette étape de l’installation. La requête effectuée lors de la réconciliation reste sommaire, sous la forme : %chaine_recherchée%.
Pour avoir des résultats moins restrictifs et une vitesse d’exécution plus rapide, il faut configurer la table des données avec l’extension FTS 5 (Full Text Search). Deux commandes SQLite sur vos données permettent de le faire.
Pour exécuter ces commandes dans DB Browser ouvrez l’onglet “Exécuter le SQL”. Dans cette fenêtre, saisissez les commandes suivantes (la commande INSERT peut demander un temps d’exécution assez long en fonction de la taille de vos données).
CREATE VIRTUAL TABLE nom_index USING FTS5 (
nom_colonne_a_indexer, --tous les noms des variables
content="nom_table", --sont personnalisables
content_rowid=rowid);
INSERT INTO nom_index(nom_index) VALUES("rebuild");
La première commande permet de créer la table qui servira d’index à la recherche plein-texte. La seconde va remplir cette table. Il est possible d’indexer plusieurs colonnes dans cette table, par exemple en ajoutant d’autres colonnes qui seront également interrogés par le service de réconciliation par la même requête.
Important
- Bien mettre les guillemets autour du nom de la table, sinon datasette ne la détecte comme ayant un index associé.
Une fois le processus terminé, vous pouvez enregistrer et relancer datasette.
Lors de la réconciliation, la vitesse de réponse est normalement plus rapide avec peut-être plus de candidats dans les options de matching. A noter que datasette-reconcile fourni également l’ensemble des services suggest.
2 - Exemple d’utilisations possibles¶
Il est possible de récupérer n’importe quel jeu de données, le transformer en CSV, l’importer dans datasette et l’interroger à l’aide d’OpenRefine (voir notre tutoriel Réconcilier avec OpenRefine).
Par exemple, pour réconcilier des noms d’auteurs avec les référentiels d’autorités de la BnF, on peut récupérer un de leurs jeux de données : sur la page des dumps nous avons sélectionné le dossier “databnf_org_authors_xml.tar.gz” lien de téléchargement (on peut aussi bien récupérer des données via le point d’accès SPARQL).
Pour préparer le jeu de données, il faut construire une base de données avec une table contenant l’identifiant BnF et les noms d’auteurs associés. Pour l’exemple, nous avons utilisé le dump de la BnF au format RDF/XML.
Pour transformer le dump RDF/XML en CSV nous avons utilisé BaseX (outil qui nécessite Java 11) pour interroger l’ensemble des fichiers XML avec des requêtes XQuery.
La première étape est d’ouvrir dans BaseX le dossier qui contient l’ensemble des fichiers XML.
Puis nous appliquons la requête suivante sur les fichiers FOAF du dump afin d’extraire l’identifiant BnF (correspond à la valeur de l’attribut rdf:about), le nom des auteurs (foaf:name et, à défaut, foaf:familyName), la date de naissance (bio:birth) et de mort (bio:death) ainsi que le lieu de naissance (rdaa:P50119).
declare namespace rdf ="http://www.w3.org/1999/02/22-rdf-syntax-ns#";
declare namespace foaf="http://xmlns.com/foaf/0.1/";
declare namespace bio="http://vocab.org/bio/0.1/";
declare namespace rdaa="http://rdaregistry.info/Elements/a/#";
declare namespace skos="http://www.w3.org/2004/02/skos/core#";
for $document in collection(databnf_person_authors_xml)
for $notice in $document/rdf:RDF/rdf:Description
where $notice/rdf:type/@rdf:resource contains text "Person"
let $identifiant := replace(replace(xs:string($notice/@rdf:about),"http://data.bnf.fr/ark:/12148/cb",""),"#about","")
let $nom := if ($notice/foaf:name/text() != "") then $notice/foaf:name/text() else $notice/foaf:familyName/text()
let $naissance := $notice/bio:birth/text()
let $mort := $notice/bio:death/text()
let $lieu_naissance := $notice/rdaa:P50119/text()
return $document/text()||$identifiant ||"$"||$nom||"$"||$naissance||"$"||$mort||"$"||$lieu_naissance
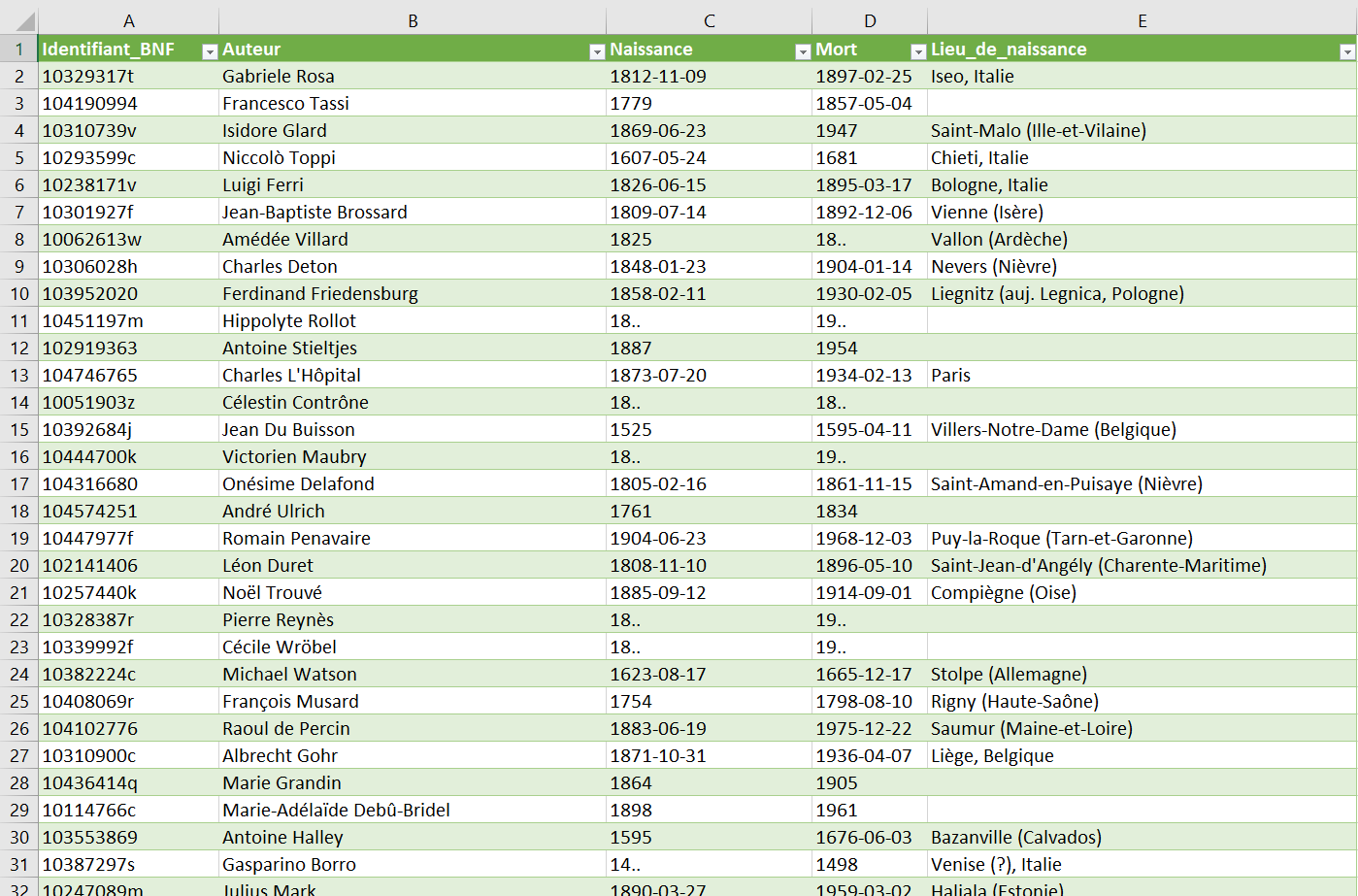
Le résultat se présente dans l’interface BaseX sous la forme d’une liste avec des valeurs séparées par des $ (c’est le séparateur choisi dans la requête). Pour sauvegarder ce résultat, il suffit de cliquer sur l’icône de sauvegarde disponible en haut à gauche de la section des résultats.
{kind=link}
Vous pouvez choisir l’intitulé des colonnes de votre fichier CSV et l’importer, comme expliqué précédemment 1.2, dans la base de données SQLite FTS5.
{kind=link}
Pour la configuration de la réconciliation, on indique à quel champ correspond l’identifiant ciblé et comment on accède au site data BnF à partir de cet identifiant (view_url) afin de faciliter la vérification. Pour les besoins de la démonstration, une limite arbitraire de 10 candidats à afficher dans la fenêtre de réconciliation (max_limit) a été fixée. Dans le fichier JSON des métadonnées, il faut nommer le service de réconciliation qu’interrogera OpenRefine (service_name) :
{
"title":"Auteurs BNF",
"databases": {
"auteurs": {
"tables": {
"authors": {
"plugins": {
"datasette-reconcile": {
"id_field": "Identifiant",
"name_field": "Auteur",
"max_limit": 10,
"view_url": "https://data.bnf.fr/fr/{{id}}",
"service_name": "Reconciliation Persons BNF"
}}}}}}}
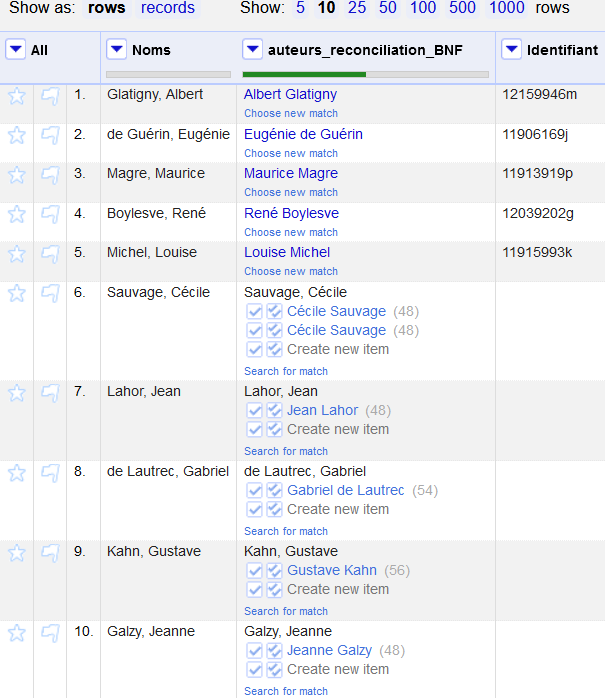
On peut désormais lancer le service datasette-reconcile et utiliser OpenRefine pour réconcilier nos données.
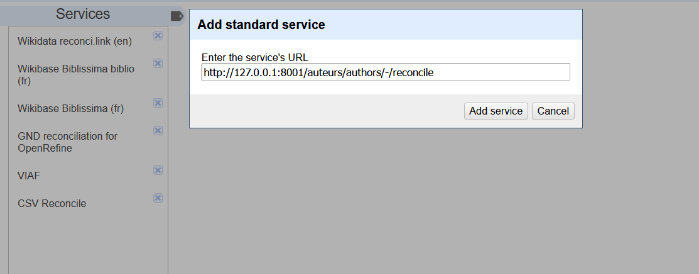
Avec cette configuration le point d’accès se trouve à l’adresse http://127.0.0.1:8001/auteurs/authors/-/reconcile. C’est celle-ci qu’il faut renseigner dans OpenRefine pour ajouter le service via le bouton Ajouter un service standard (ou Add standard service) disponible dans la fenêtre de réconciliation.
{kind=link}
Il ne reste plus qu’à réconcilier ses entités auteurs avec le référentiel de la BnF, et tout cela en local ! Même s’il n’offre pas toutes les possibilités et la puissance qu’un outil de réconciliation peut avoir avec l’endpoint de Wikidata, datasette-reconcile vous permettra d’accélérer vos alignements sur des jeux de données qui ne disposent pas d’API de réconciliation.
{kind=link}
Si vous souhaitez en savoir plus, n’hésitez pas à consulter la page GitHub de datasette-reconcile. Vous pouvez également vous plonger dans le code Python de l’application.
Citer cette page
LANGELÉ Florian (ingénieur d’études), “Réconcilier avec Datasette”, Documentation Biblissima+, 2025